유튜브 영상 대사 찾아주는 사이트를 만들어보자 (feat Next.js, API route)
침착맨 대사 찾기 https://chimlang.pythonanywhere.com/ 사이트를 재밌게 봤었는데 비슷하게 만들어보고 싶어 제작했습니다.
제작자분은 Python 크롤링을 통해 자막 데이터를 추출하신 것으로 보였는데, 순수 브라우저 기반에서도 가능한지 궁금해 휴일에 빠르게 재미삼아 만들어 봤습니다.
좋아하는 유튜브 영상에서 찾고 싶은 대사를 찾아보세요!
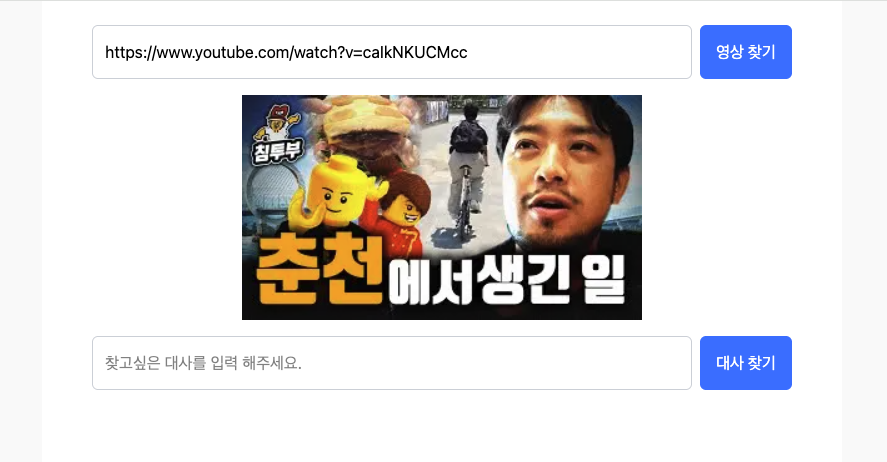
원하는 유튜브 영상의 URL을 긁어 검색합니다.
한국어 자동 자막 생성 데이터를 영상 검색시 가져옵니다.
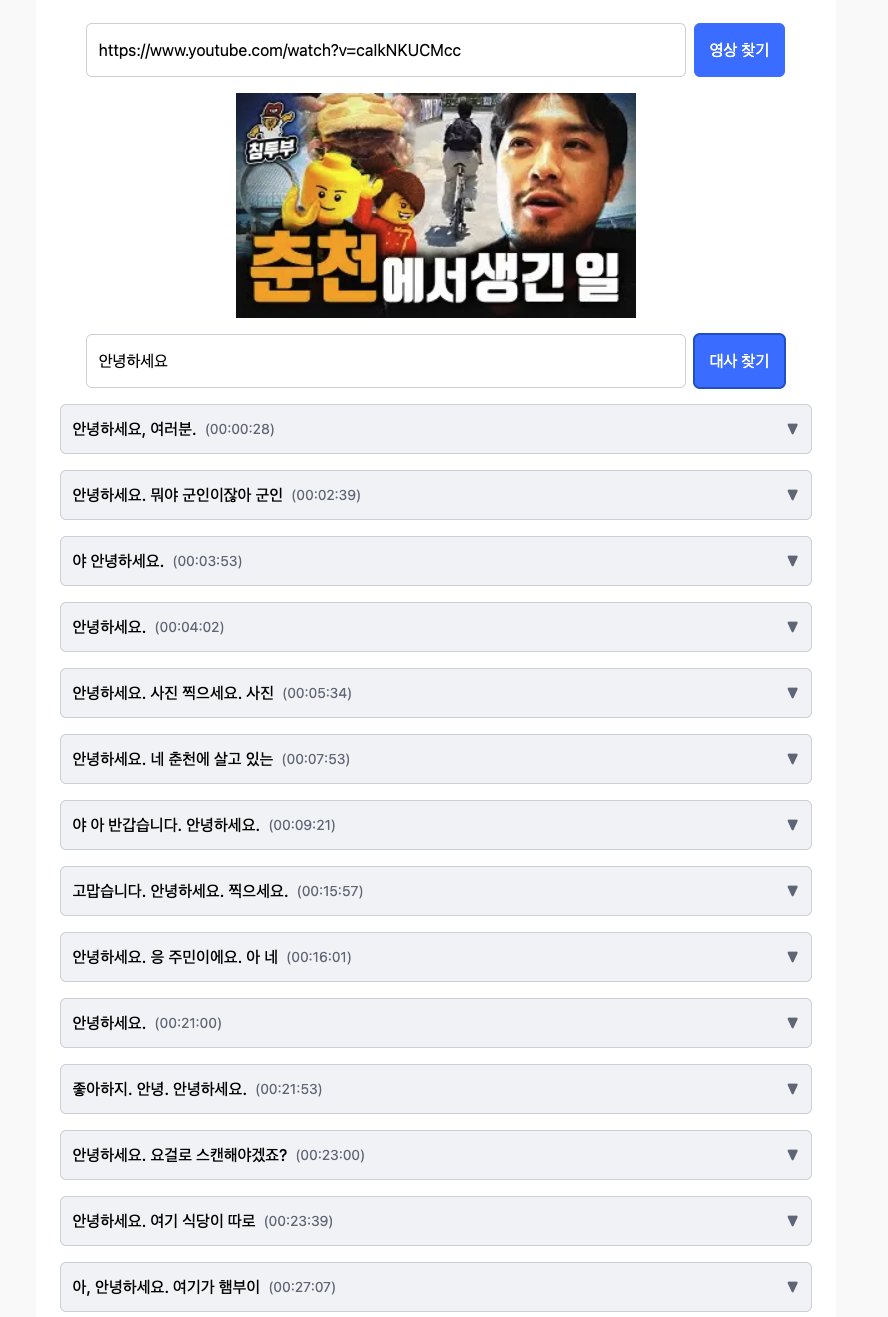
자막 데이터를 성공적으로 가져왔다면 원하는 대사를 검색 가능합니다.
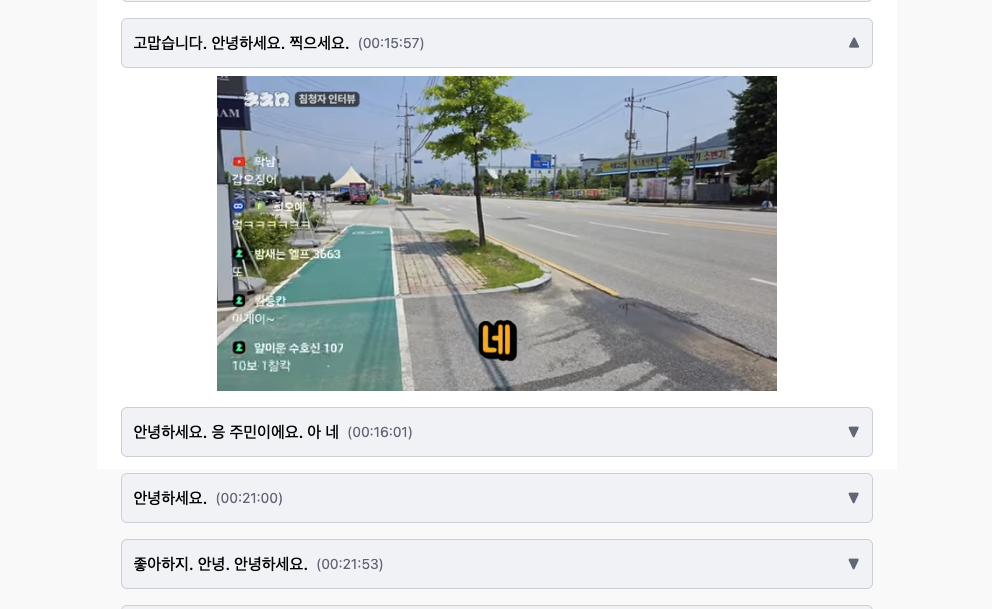
원하는 대사를 찾았다면 플레이어와 함께 대사 시작 시간에 맞춰 플레이어를 재생 가능합니다.
기능 구현
CORS 에러를 피하기 위해 Next.js의 API Route 기능을 사용했습니다.
// ...
// @/app/routes/api/captions/route.ts
const videoRes = await fetch(`https://www.youtube.com/watch?v=${videoId}`);
const html = await videoRes.text();
const match = html.match(/ytInitialPlayerResponse\s*=\s*(\{.+?\});/s); // HTML에서 자막 관련 JSON이 포함된 스크립트 추출
//...
const playerResponse = JSON.parse(match[1]); // 추출된 JSON 문자열을 파싱
const tracks =
playerResponse?.captions?.playerCaptionsTracklistRenderer?.captionTracks; // 자막 트랙 정보 접근
// ...
// 자막 중 언어 코드가 "ko"(한국어)인 트랙 찾기
const koreanTrack = tracks.find((t: any) => t.languageCode === "ko");
const baseUrl = koreanTrack.baseUrl.includes("&fmt=json3")
? koreanTrack.baseUrl
: `${koreanTrack.baseUrl}&fmt=json3`; // 자막 API 요청 URL 구성 (fmt=json3 포맷 사용)
// 자막 JSON 데이터 요청
const captionResponse = await fetch(`${baseUrl}&fmt=json3`);
const captionJson = await captionResponse.json();자막 데이터를 가져오는 코드 일부 입니다. 핵심 로직만 간략히 작성했습니다.
🚀 실행 방법
git clone https://github.com/glowforever96/find-youtube-lines.git
cd find-youtube-lines
npm install
npm run dev아쉬운점
실제로 Vercel로 배포한 이후에는 개발 환경과 달리 유튜브의 요청 차단으로 인해 데이터를 가져오는 데 실패했습니다. 추출한 HTML의 형식도 로컬에서와는 다른 모습이었습니다.
또한 유튜브 공식 API에서는 영상 자막 데이터를 직접적으로 제공하지 않기 때문에 유튜브 HTML을 통째로 요청한뒤 내부 스크립트 데이터를 추출하는 로직이기에 많이 불안정합니다. 한번에 받아오지 못하고 여러 번 요청을 시도하면 정상적으로 자막을 받아오는 경우가 좀 있었습니다.
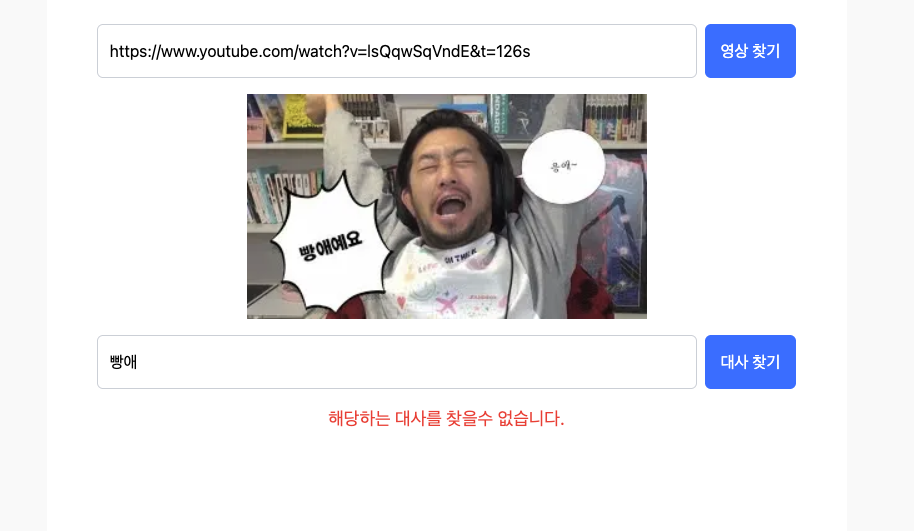
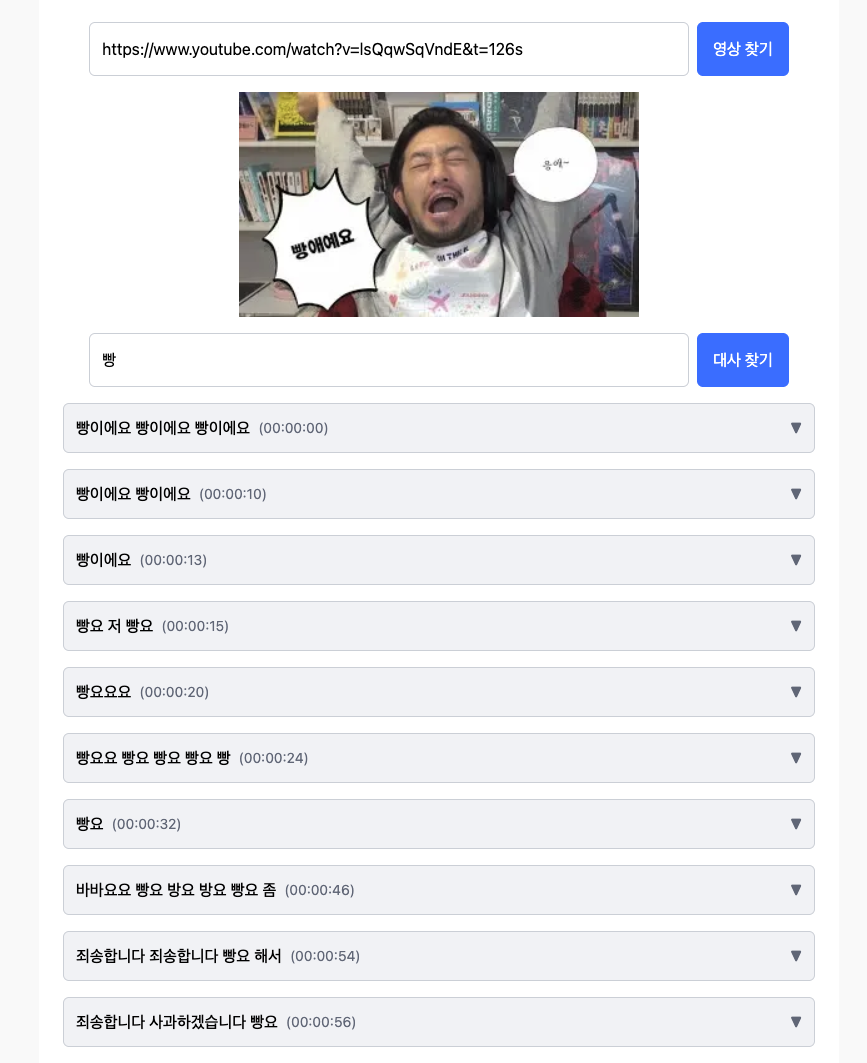
유튜브 한국어 자동 생성 자막은 부정확해 정확도가 높지는 않습니다. (빵애 라는 대사가 자주 나오는 영상이지만 검색하지 못함)